Computing a Rolling Median¶
This describes how to code up a rolling median using a SkipList in both C++ and Python.
A rolling median operation means, for a SkipList, an insert(new_value) then at(middle) then remove(old_value).
The number of operations to calculate a rolling median is the data length minus the window length.
The same approach can be used for a rolling percentile.
Rolling Median in C++¶
Here is a reasonable C++ attempt at doing that with the arguments:
data- A vector of data of typeTof lengthL.win_length- a ‘window’ size. The median is computed over this number of values.result- a destination vector for the result. This will either end up withL - win_lengthvalues.
1#include "SkipList.h"
2
3template<typename T>
4RollingMedianResult rolling_median(const std::vector<T> data,
5 size_t win_length,
6 std::vector<T> &result) {
7 if (win_length == 0) {
8 return ROLLING_MEDIAN_WIN_LENGTH;
9 }
10 OrderedStructs::SkipList::HeadNode<T> sl;
11
12 result.clear();
13 std::vector<T> buffer;
14 for (size_t i = 0; i < data.size(); ++i) {
15 sl.insert(data[i]);
16 if (i >= win_length) {
17 if (win_length % 2 == 1) {
18 result.push_back(sl.at(win_length / 2));
19 } else {
20 /* Even length so average */
21 sl.at((win_length - 1) / 2, 2, buffer);
22 assert(buffer.size() == 2);
23 result.push_back(buffer[0] / 2 + buffer[1] / 2);
24 }
25 sl.remove(data[i - win_length]);
26 }
27 }
28 return ROLLING_MEDIAN_SUCCESS;
29}
A full example is the RollingMedian::rolling_median_lower_bound function in RollingMedian.h.
If you are working with C arrays (such as Numpy arrays) then this C’ish approach might be better, again error checking omitted:
1#include "SkipList.h"
2
3template <typename T>
4void rolling_median(const T *src, size_t count, size_t win_length, T *dest) {
5
6 OrderedStructs::SkipList::HeadNode<T> sl;
7 const T *tail = src;
8
9 for (size_t i = 0; i < count; ++i) {
10 sl.insert(*src);
11 if (i + 1 >= win_length) {
12 *dest = sl.at(win_length / 2);
13 ++dest;
14 sl.remove(*tail);
15 ++tail;
16 }
17 ++src;
18 }
19}
Multidimensional Numpy arrays have a stride value which is omitted in the above code but is simple to add. See RollingMedian.h and test/test_rolling_median.cpp for further examples.
Rolling percentiles require a argument that says what fraction of the window the required value lies. Again, this is easy to add.
Even Window Length¶
The above code assumes that if the window length is even that the median is at (window length - 1) / 2.
A more plausible median for even sized window lengths is the mean of (window length - 1) / 2 and
window length / 2.
This requires that the mean of two types is meaningful which it will not be for strings. In that case you will get this compilation error:
RollingMedian.h:91:52: error: invalid operands to binary expression ('value_type' (aka 'std::string') and 'int')
result.push_back(buffer[0] / 2 + buffer[1] / 2);
~~~~~~~~~ ^ ~
One remedy for this is to use the RollingMedian::rolling_median_lower_bound function.
This always uses the lower bound so works correctly for odd sized window lengths.
For even sized window lengths this chooses the lower value rather than averaging two values.
This is useful for, say, strings that can not be averaged.
C++ Performance¶
Here is a plot of the time taken to compute a rolling median on one million values using different window sizes. The time here is in ns/result and the number of results is 1e6 - window size. Given a data length of 1m then a window length of 1000 this would mean 999,000 operations. A window length of 500,000 this would mean 500,000 operations.
A window size of 1000 and 1m values (the size of the SkipList) takes around 750 ns/value or 0.75 second in total.

The test function is perf_roll_med_by_win_size() in src/cpp/test/test_performance.cpp.
Rolling Median in Python¶
Here is an example of computing a rolling median of a numpy 1D array.
This creates an array with the same length as the input starting with window_length NaN s:
1import numpy as np
2
3import orderedstructs
4
5def simple_python_rolling_median(vector: np.ndarray,
6 window_length: int) -> np.ndarray:
7 """Computes a rolling median of a numpy vector returning a new numpy
8 vector of the same length.
9 NaNs in the input are not handled but a ValueError will be raised."""
10 if vector.ndim != 1:
11 raise ValueError(
12 f'vector must be one dimensional not shape {vector.shape}'
13 )
14 skip_list = orderedstructs.SkipList(float)
15 ret = np.empty_like(vector)
16 for i in range(len(vector)):
17 value = vector[i]
18 skip_list.insert(value)
19 if i >= window_length - 1:
20 # // 4 for lower quartile
21 # * 3 // 4 for upper quartile etc.
22 median = skip_list.at(window_length // 2)
23 skip_list.remove(vector[i - window_length + 1])
24 else:
25 median = np.nan
26 ret[i] = median
27 return ret
This can be called thus:
np_array = np.arange(10.0)
print('Original:', np_array)
result = simple_python_rolling_median(np_array, 3)
print(' Result:', result)
And the result will be:
Original: [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
Result: [nan nan 1. 2. 3. 4. 5. 6. 7. 8.]
Of course this Python code could be made much faster by using a Python C Extension.
Python Performance¶
Here is a plot of the time taken to compute a rolling median on one million values using different window sizes. The time here is in ns/result and the number of results is 1e6 - window size. Given a data length of 1m then a window length of 1000 this would mean 999,000 operations. A window length of 500,000 this would mean 500,000 operations.
A window size of 1000 and 1m values (the size of the SkipList) takes around 750 ns/value or 0.75 second in total.

Performance Comparison of C++ and Python¶
Here is the C++ performance plotted along with the Python performance.
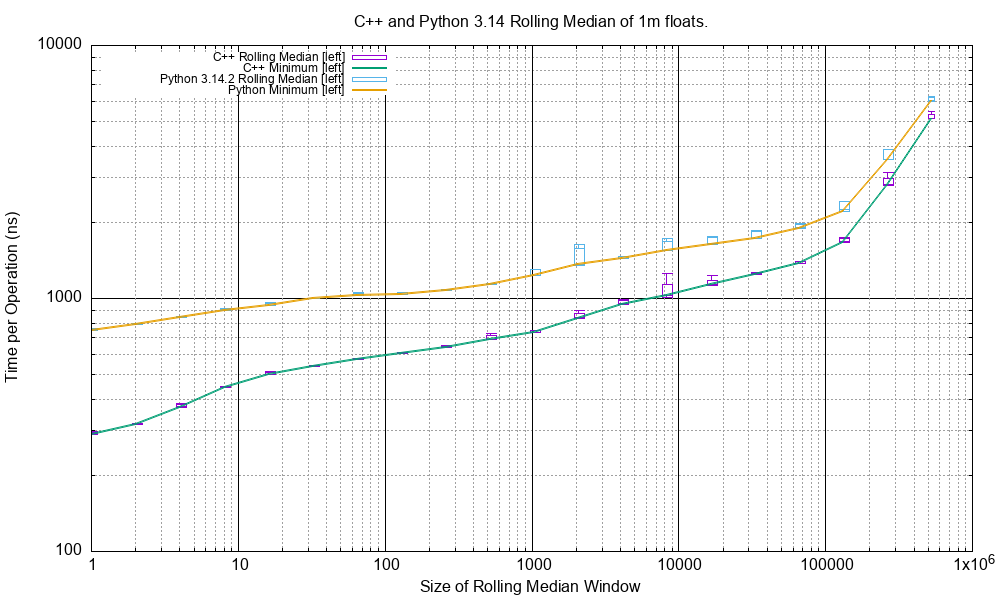
As expected C++ is around 2x faster.
But Python has another trick up its sleeve that can make it outperform C++ decisively; multiprocessing with shared memory.
Rolling Median in Python with multiprocessing.shared_memory¶
An exiting development in Python 3.8+ is multiprocessing.shared_memory This allows a parent process to share memory with its child processes.
In this example we are going to compute a rolling median on a 2D numpy array where each child process works on a single column of the same array and writes the result to a shared output array. There will be two shared memory areas; a read one with the input data and a write one with the result from all the child processes There will be two corresponding numpy arrays the input that we are given and the output numpy array that we create.
The only copying going on here is the initial copy of the input array into shared memory and then the final copy, when all child processes have completed of that shared memory to a single numpy array.
Pictorially:
1Parent Children
2====== ========
3Copies the numpy array to the input SharedMemory
4Creates the output SharedMemory
5Launches n child processes...
6\>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>\
7 Work on part of the input SharedMemory
8 Write to the output SharedMemory
9 ...
10/<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<</
11When all child processes complete...
12Copies output SharedMemory to a new numpy array
13Releases both SharedMemory resources.
Note
This solution assumes that you are given a numpy array that you need to process. An alternative solution is to create a shared memory object, create an empty numpy array that uses the shared memory buffer, populate that buffer and pass the buffer to the child processes. This would save the cost, in time and memory, of the first copy operation.
Code¶
The exemplar code is in tests/benchmarks/roll_med_sh_mem.py
Note
The reason for the odd code location is the way that the orderedstructs package is,
for historical reasons, constructed entirely in C.
See PyInit_orderedstructs() in src/cpy/cOrderedStructs.cpp.
This means that it is not possible to combine pure Python and C code in the orderedstructs package.
Specifically orderedstructs does not have a __path__ attribute that allows it to import pure Python modules
from that path.
In future this might change to be more like, say, pymemtrace that is able to mix C and pure Python code
in the same package.
These are the essential imports and a utility function:
1import multiprocessing
2# Python 3.8+, need to be specific about importing this.
3from multiprocessing import shared_memory
4import typing
5
6import numpy as np
7
8import orderedstructs
9
10def np_data_pointer(a: np.ndarray) -> int:
11 """The address of the actual data. 'data pointer' in np.info()."""
12 return a.__array_interface__["data"][0]
Firstly here is the rolling median function that will be used by the child processes, it works on a specific column of a numpy array. Error handling and logging are omitted for clarity:
1def rolling_median_of_column(read_array: np.ndarray,
2 window_length: int, column_index: int,
3 write_array: np.ndarray) -> None:
4 """Computes a rolling median of given column and writes out the
5 results to the write array.
6
7 This is called by a child process.
8
9 This fills the initial column values with NaN where there is
10 not enough data for a rolling median of window_length.
11 """
12 skip_list = orderedstructs.SkipList(float)
13 for i in range(len(read_array)):
14 value = read_array[i, column_index]
15 skip_list.insert(value)
16 if i >= window_length:
17 median = skip_list.at(window_length // 2)
18 skip_list.remove(read_array[i - window_length, column_index])
19 else:
20 median = np.nan
21 write_array[i, column_index] = median
Now some code that wraps the low level multiprocessing.shared_memory.SharedMemory class that can be
used by the parent process.
This is a dataclass that records essential information about the array and includes the SharedMemory object
itself.
We will call it an SharedMemoryArraySpecification, it is pretty simple, just a dataclass
(some unimportant functions omitted here):
1from multiprocessing import shared_memory
2
3@dataclasses.dataclass
4class SharedMemoryArraySpecification:
5 """A PoD class that contains the data needed for
6 managing a shared_memory.SharedMemory.
7
8 Typical usage, given ``arr: np.ndarray``::
9
10 from multiprocessing import shared_memory
11
12 shm = shared_memory.SharedMemory(create=True, size=arr.nbytes)
13 array_spec = SharedMemoryArraySpecification(
14 arr.shape, arr.dtype, arr.nbytes, shm,
15 )
16 """
17 shape: typing.Tuple[int, ...]
18 dtype: np.dtype
19 nbytes: int
20 shm: shared_memory.SharedMemory
21
22 @property
23 def name(self) -> str:
24 return self.shm.name
25
26 def close(self) -> None:
27 """Close the file descriptor/handle to the shared memory
28 from this instance."""
29 self.shm.close()
30
31 def close_and_unlink(self) -> None:
32 """Delete the underlying shared memory block.
33 This should be called only once per shared memory block
34 regardless of the number of handles to it, even in other
35 processes."""
36 self.close()
37 self.shm.unlink()
Now a function that takes a numpy array and uses shared_memory.SharedMemory to return
a SharedMemoryArraySpecification.
Optionally this copies the numpy array into the shared memory for the read array.
We write this as a context manager.
Error handling and logging are omitted for clarity:
1@contextlib.contextmanager
2def create_shared_memory_array_spec_close_unlink(
3 arr: np.ndarray,
4 copy_array: bool,
5) -> SharedMemoryArraySpecification:
6 """Context manager that creates a Shared Memory instance and,
7 optionally, copies the numpy array into it.
8 The Shared Memory instance is closed and unlinked on exit."""
9 shm = shared_memory.SharedMemory(create=True, size=arr.nbytes)
10 array_spec = SharedMemoryArraySpecification(
11 arr.shape, arr.dtype, arr.nbytes, shm
12 )
13 try:
14 if copy_array:
15 # Copy the numpy array into shared memory.
16 array_view = np.ndarray(
17 array_spec.shape,
18 dtype=array_spec.dtype, buffer=array_spec.shm.buf
19 )
20 array_view[:] = arr[:]
21 yield array_spec
22 finally:
23 array_spec.close_and_unlink()
Next is a context manager that will wrap a numpy array around a SharedMemoryArraySpecification
On exit this automatically releases the reference to the shared memory from the child process
(but does not unlink that memory):
1@contextlib.contextmanager
2def recover_array_from_shared_memory_and_close(
3 array_spec: SharedMemoryArraySpecification,
4) -> np.ndarray:
5 """A context manager as a wrapper around a SharedMemoryArraySpecification.
6 This yields a view on the numpy input or output array and ensures that the
7 shared memory is closed on __exit__."""
8 array_shm = shared_memory.SharedMemory(name=array_spec.name)
9 array_view = np.ndarray(
10 array_spec.shape, array_spec.dtype, buffer=array_shm.buf
11 )
12 try:
13 yield array_view
14 finally:
15 array_shm.close()
And use it in the child process, once for reading and once for writing. Error handling and logging are omitted for clarity:
1def compute_rolling_median_2d_from_index(
2 read_spec: SharedMemoryArraySpecification,
3 window_length: int, column_index: int,
4 write_spec: SharedMemoryArraySpecification,
5) -> int:
6 """Computes a rolling median of the 2D read array and
7 window length and writes it to the 2D write array.
8
9 This function is passed to multiprocessing to be invoked
10 by the child process.
11 """
12 with recover_array_from_shared_memory_and_close(read_spec) as read_arr:
13 with recover_array_from_shared_memory_and_close(write_spec) as write_arr:
14 write_count = rolling_median_of_column(
15 read_arr, window_length, column_index, write_arr
16 )
17 return write_count
Finally a function to copy the output shared memory to a new numpy array:
1def copy_shared_memory_into_new_numpy_array(
2 write_array_spec: SharedMemoryArraySpecification,
3) -> np.ndarray:
4 """With the output SharedMemoryArraySpecification
5 this creates a new numpy array and copies the shared memory into it."""
6 temp_write = np.ndarray(
7 write_array_spec.shape,
8 dtype=write_array_spec.dtype,
9 buffer=write_array_spec.shm.buf
10 )
11 write_array = np.empty(
12 write_array_spec.shape,
13 dtype=write_array_spec.dtype,
14 )
15 write_array[:] = temp_write[:]
16 return write_array
Finally here is the code for the parent process that puts this all together. Error handling and logging are omitted for clarity:
1def compute_rolling_median_2d_mp(
2 read_array: np.ndarray,
3 window_length: int, num_processes: int,
4) -> np.ndarray:
5 """Compute a rolling median of a numpy 2D array using
6 multiprocessing and shared memory.
7 This is the top level call and is run within the parent process.
8
9 This returns a np.ndarray of the same shape as the input with the
10 rolling medians.
11 Rows of this up to the window_length will be NaN.
12 """
13 # Limit number of processes if the number of columns is small.
14 if read_array.shape[1] < num_processes:
15 num_processes = read_array.shape[1]
16 with create_shared_memory_array_spec_close_unlink(
17 read_array, copy_array=True,
18 ) as read_array_spec:
19 with create_shared_memory_array_spec_close_unlink(
20 read_array, copy_array=False,
21 ) as write_array_spec:
22 # Create the tasks.
23 tasks = []
24 for column_index in range(read_array.shape[1]):
25 tasks.append(
26 (read_array_spec, window_length, column_index, write_array_spec)
27 )
28 # Create the pool and apply the tasks.
29 mp_pool = multiprocessing.Pool(processes=num_processes)
30 pool_apply = [
31 mp_pool.apply_async(
32 compute_rolling_median_2d_from_index, t
33 ) for t in tasks
34 ]
35 _write_counts = [r.get() for r in pool_apply]
36 write_array = copy_shared_memory_into_new_numpy_array(write_array_spec)
37 return write_array
This is the function that we are going to time so it includes:
Copying the numpy array to shared memory.
Creating the output shared memory.
Computing the rolling median with child processes.
Copying the output shared memory to a new numpy array.
Disposing of any temporaries.
Performance¶
Low Level Shared Memory Performance¶
First some low level performance benchmarks for multiprocessing.shared_memory.
Here is the cost of creating an SharedMemory object with (for reading) and without (for writing) copying from a numpy array.

The non-copy cost is negligible. The copy cost is around 1,600 MB/s for 64bit floats.
And here is the cost of creating a new numpy array from the SharedMemory object:

The copy cost is around 1,600 MB/s for 64bit floats.
Performance on a Table of Floats¶
The table has 134,217,728 floats (1GB of data) and the tests are run with with different shapes. The rolling median window is 21. The platform was Mac OS X with 4 cores and hyper-threading.
Here is the total time to create the rolling median with this amount of data of different shapes for different number of processes.
The test code is in tests/benchmarks/test_benchmark_SkipList_rolling_median_sh_mem.py and is normally skipped as it can take up to six hours per Python version.

For reference 100 seconds is 745 nanoseconds per operation.
Here is comparison of different shapes for different number of processes compared with a single process.

That is for the full 1GB array, but how much data is needed for shared memory to be an effective technique?
The following results are from the code in tests/unit/_test_rolling_median_shared_memory.py.
Columns: 16¶
In this test a 16 column array is created with up to 8,388,608 rows. This is up to 134,217,728 entries at 8 bytes a float this is 1,073,741,824 bytes (1GB) in total. Running this on 16 column arrays with 1m rows with processes from 1 to 16 gives the following execution times.

Comparing the speed of execution compared to a single process gives:

Clearly there is some overhead so it is not really worth doing this for less that 100,000 rows. The number of processes equal to the number of CPUs is optimum, twice that might give a small advantage.
Columns: 1024¶
In this test a 1024 column array is created with up to 131,072 rows. This is up to 134,217,728 entries at 8 bytes a float this is 1,073,741,824 bytes (1GB) in total. Running this on 1024 column arrays with up to 131,072 rows with processes from 1 to 16 gives the following execution times.

Comparing the speed of execution compared to a single process gives:

Clearly there is some overhead so it is not really worth doing this for less that 1,000 rows or so.
Columns: 65536¶
In this test a 65,536 column array is created with up to 2048 rows. This is up to 134,217,728 entries at 8 bytes a float this is 1,073,741,824 bytes (1GB) in total. Running this on 65,536 column arrays with up to 2048 rows with processes from 1 to 16 gives the following execution times.

Comparing the speed of execution compared to a single process gives:

The overhead, by number of columns is very low.
Comparison By Shape¶
Here is the results of the time to compute a rolling median with a single process and different number of columns and different array shapes by array size (number of rows):

Here is the results of the time to compute a rolling median with four processes and different number of columns and different array shapes by array size (number of rows):

Here is all the data plotted together for comparison:

The rate is, perhaps, more revealing:

Summary¶
For different table shapes using four simultaneous processes on a four CPU machine. The second column shows the number of rows need to get a 3x performance on a four CPU machine. The third column (“Best”) shows the maximum speedup.
Here is a summary of the performance gain:
Columns |
~Rows for 3x |
Best |
Notes |
|---|---|---|---|
16 |
800,000 |
3.3x |
|
1024 |
8,000 |
3.3x |
|
65536 |
128 |
3.0x |
The relative performance improvement between a single process and four processes is very consistent:

So, in summary, setting up shared memory really comes into its own with data sets of 1m+. It is not advised for less than 100,000 data points.
Here is a typical comparison between C++ and Python working on large data sets on a four CPU machine:
Environment |
Time/op (ns) |
Notes |
|---|---|---|
C++, single process |
500 |
|
Python, single process |
900 |
|
Python, shared memory, processes=1 |
1000 |
|
Python, shared memory, processes=4 |
350 |
So Python can beat C++!
Memory Usage¶
What I would expect in processing a 100Mb numpy array. Values are in Mb.
Action |
Memory Delta (Mb) |
Total Memory (Mb) |
|---|---|---|
Create a ‘read’ numpy array. |
+100 |
100 |
Create a ‘read’ shared memory object. |
+100 |
200 |
Copy the ‘read’ array into ‘read’ shared memory. |
0 or very small. |
200 |
Create a ‘write’ shared memory object. |
+100 |
300 |
Calculate the rolling median and write into the ‘write’ shared memory object. |
0 or very small. |
300 |
Create an empty ‘write’ numpy array. |
+100 |
400 |
Copy the ‘write’ shared memory into the ‘write’ numpy array. |
0 or very small. |
400 |
Unlink the ‘read’ shared memory |
-100 |
300 |
Unlink the ‘write’ shared memory. |
-100 |
200 |
Delete the ‘read’ numpy array when de-referenced. |
-100 |
100 |
Delete the ‘write’ numpy array when de-referenced. |
-100 |
Nominal. |
Here are the actual results running on Mac OS X. Two things are noticeable:
Creating the shared memory object has no memory cost. It is only when data is copied into it that the memory is allocated and that is incremental.
The RSS shown here is collected from
psutiland it looks like this is including shared memory so there may be double counting here.psutilcan not identify shared memory on Mac OS X, it can on Linux.
Here is the breakdown of the RSS memory profile of processing a numpy array with 6m rows with 2 columns (100Mb) with a parent [P] and two child processes [0] and [1]. The change in RSS is indicated by “d” (if non-zero). Values are in Mb.
Action |
P |
dP |
0 |
d0 |
1 |
d1 |
Notes |
|---|---|---|---|---|---|---|---|
Parent start |
30 |
+30 |
Normal Python executable. |
||||
Create numpy array |
130 |
+100 |
Cost of creating a 100Mb numpy array. |
||||
Create read shared memory |
130 |
No immediate memory cost. |
|||||
Copy numpy array into shared memory |
225 |
+95 |
|||||
Create write shared memory |
225 |
No immediate memory cost. |
|||||
Child start |
23 |
+23 |
23 |
+23 |
Normal Python executable. |
||
Rolling median start |
23 |
23 |
|||||
Rolling median 25% |
71 |
+48 |
71 |
+48 |
Incremental memory increase, similar to copy on write. |
||
Rolling median 50% |
119 |
+48 |
119 |
+48 |
|||
Rolling median 75% |
166 |
+47 |
166 |
+47 |
|||
Rolling median complete |
214 |
+48 |
214 |
+48 |
Peak figure, it looks like the RSS for the child processes is including both shared memory areas (192Mb). |
||
Close write shared memory |
119 |
-95 |
119 |
-95 |
|||
Close read shared memory |
23 |
-96 |
23 |
-96 |
Child process now using the normal memory for a Python process. |
||
After child processes complete. |
227 |
+2 |
Children have written to write shared memory which is now included in the parent memory RSS. |
||||
After creating empty numpy write array. |
227 |
NOTE: Buffer is lazily allocated. |
|||||
After writing write shared memory to numpy write array. |
419 |
+192 |
Not sure why this twice what is expected (100Mb). |
||||
After unlink write array spec. |
321 |
-98 |
|||||
After unlink read array spec. |
226 |
-95 |
Discard read array shared memory. Numpy read and write arrays still exist, 100Mb each. |
||||
Parent process ends. |
227 |
Read array and write array discarded. See note below. |
Note
There is an interesting quirk here, the array is 6m rows with 2 columns and has a residual memory of 227Mb.
This is not reduced by a gc.collect().
This does not increase if the same function calls are repeated.
If the array is changed to 16m rows, 2 columns (260Mb) the residual memory is 35Mb, typical for a minimal
Python process.
Handling NaNs¶
Not-a-number (NaN) values can not be inserted into a Skip List as they are not
comparable to anything (including themselves).
An attempt to call insert(), index(), has(), remove() with a NaN will raise an error.
In C++ this will throw a OrderedStructs::SkipList::FailedComparison.
In Python it will raise a ValueError.
This section looks at handling NaNs in Python.
Here are several ways of handling NaNs:
Propogate the Exception.
Make the Median NaN.
Forward Filling.
Propogate the Exception¶
Here is a rolling median that will raise a ValueError if there is a NaN in the input.
1def rolling_median_no_nan(vector: typing.List[float],
2 window_length: int) -> typing.List[float]:
3 """Computes a rolling median of a vector of floats and returns the results.
4 NaNs will throw an exception."""
5 skip_list = orderedstructs.SkipList(float)
6 ret: typing.List[float] = []
7 for i in range(len(vector)):
8 value = vector[i]
9 skip_list.insert(float(value)) # This will raise a ValueError on NaN
10 if i >= window_length:
11 median = skip_list.at(window_length // 2)
12 skip_list.remove(vector[i - window_length])
13 else:
14 median = math.nan
15 ret.append(median)
16 return ret
Make the Median NaN¶
Here is a rolling median that will make the median NaN if there is a NaN in the input. Incidentally this is the approach that numpy takes.
1def rolling_median_with_nan(vector: typing.List[float],
2 window_length: int) -> typing.List[float]:
3 """Computes a rolling median of a vector of floats and returns the results.
4 NaNs will be consumed."""
5 skip_list = orderedstructs.SkipList(float)
6 ret: typing.List[float] = []
7 for i in range(len(vector)):
8 value = vector[i]
9 if math.isnan(value):
10 median = math.nan
11 else:
12 skip_list.insert(float(value))
13 if i >= window_length:
14 median = skip_list.at(window_length // 2)
15 remove_value = vector[i - window_length]
16 if not math.isnan(remove_value):
17 skip_list.remove(remove_value)
18 else:
19 median = math.nan
20 ret.append(median)
21 return ret
The first row is the input, the second the output. Window length is 5:
[0.0, math.nan, 2.0, 3.0, 4.0, 5.0, 6.0, math.nan, 8.0, 9.0],
[math.nan, math.nan, math.nan, math.nan, math.nan, 3.0, 4.0, math.nan, 4.0, 5.0],
Forward Filling¶
Another approach is to replace the NaN with the previous value. This is very popular in FinTech and is commonly know as Forward Filling. Here is an implementation:
1def forward_fill(vector: typing.List[float]) -> None:
2 """Forward fills NaNs in-place."""
3 previous_value = math.nan
4 for i in range(len(vector)):
5 value = vector[i]
6 if math.isnan(value):
7 vector[i] = previous_value
8 if not math.isnan(value):
9 previous_value = value
10
11def rolling_median_with_nan_forward_fill(vector: typing.List[float],
12 window_length: int) -> typing.List[float]:
13 """Computes a rolling median of a vector of floats and returns the results.
14 NaNs will be forward filled."""
15 forward_fill(vector)
16 return rolling_median_no_nan(vector, window_length)
The first row is the input, the second the output. Window length is 5:
[0.0, math.nan, 2.0, 3.0, 4.0, 5.0, 6.0, math.nan, 8.0, 9.0],
[math.nan, math.nan, math.nan, math.nan, math.nan, 2.0, 3.0, 4.0, 5.0, 6.0],
Another example where [3] is now a NaN, the first row is the input, the second the output. Window length is 5:
[0.0, math.nan, 2.0, math.nan, 4.0, 5.0, 6.0, math.nan, 8.0, 9.0],
[math.nan, math.nan, math.nan, math.nan, math.nan, 2.0, 2.0, 4.0, 5.0, 6.0],
There is no ‘right way’ to handle NaNs. They are always problematic. For example what is the ‘right way’ to sort a sequence of values that may include NaNs?